
UberGuy
-
Posts
657 -
Joined
-
Last visited
-
Days Won
1
Content Type
Profiles
Forums
Events
Store
Articles
Patch Notes
Posts posted by UberGuy
-
-
The "Raw Data" download archives now should offer to be downloaded with a filename based on the revision of data you're looking at. So instead of (for example) raw_data_cryptic.zip, you should be offered (currently) raw_data_cryptic-20220727_5016.zip.
The CoD site does not hold archives from old revisions, and the underlying filenames on the site are still always just raw_data_homecoming.zip or raw_data_cryptic.zip - only the filename presented when saving it should now change intelligently. This behavior relies on features of modern browsers to handle a couple of different ways to set the desired filename on download. In the CoD site code, the download attribute of the HTML anchor tag is used, and also the content-disposition response header set by the server when responding to a request for the file.
If you are for some reason retrieving the file programmatically outside of a browser, use the content-disposition response header to set the filename locally. Some HTTP libraries are smart enough to do this for you, but if yours is not, it should let you inspect that header to see what the revision-specific filename should be.
Edit: Because I have not regenerated Live (Homecoming) site data and likely won't until Page 4 goes live, the homecoming archive doesn't have the content-disposition header. It will pick it up the next time I regenerate it.
-
 1
1
-
-
Site code has been updated to both (hopefully) address the above problems and to add support for new things found in the Alpha site data.
There was an Alpha patch today, so I'm currently regenerating its data. I'm heading to bed soon, so the data push will probably happen in the morning.
Edit: Nah, I lied. The missus stayed up later than planned so everything finished building and uploading.

-
 1
1
-
 1
1
-
1
-
-
It took some digging, but I now know that if a power has a bogus table name like that, the result is the same as looking up melee_ones or ranged_ones - that's to say the value is always 1.0 at all levels for all ATs.
I'll make a similar update to the logic in CoD - I never knew before what would happen in such a case, so I just bailed out. In this case, it happens to do what is almost certainly wanted in this case. (Asking for a table called "Ones" surely meant the value to be one at every level.)
-
2
-
-
On 7/3/2022 at 2:43 PM, BillyMailman said:
Live data, none of the activation icons are showing for me.
Hard refreshed and cache-busted everything.
Notably, they're showing on the alpha data.
Sorry that I haven't looked into this in a while.
I'm betting that changes to support Alpha changes busted something for Live. I'll look into fixing it, as I've no idea how close Page 4 is to go-live. (If it was imminent, I might let this slide.) Edit: Yep, I added code to display new fields that only exist yet for Alpha and their absence is blowing up the icon rendering for Live.
That "Undefined data" message you're seeing for Repulsion Field means the data is literally missing, not just null. This might be another case of an Alpha change breaking something, or it could be something else (this may have been broken before...). That it is so limited is interesting, but at least I have one very specific place to look! Edit: This is a problem with this power. It is using the scaling table "Ones". There is no such table defined. There is only "melee_ones" and "ranged_ones". This issue is also present in singy's Gravitational Pull power.
-
2
-
-
It's there now.
 It didn't take all this time, but it did take a bit just to figure out what actually uses the new stuff on Alpha to validate my changes worked.
It didn't take all this time, but it did take a bit just to figure out what actually uses the new stuff on Alpha to validate my changes worked.
As is often the case, I spent more time coming up with a new icon than I did coding.
-
 1
1
-
-
Working on getting the latest Cryptic patch updated. This one included some powers data changes. I'm up to speed on what changed and had code changes ready so this shouldn't take long.
-
1
-
-
Found it. I had upgraded a software library in the Python side of the extracter/parser which had a breaking API change. If you wanted to set a default value for a missing field, you used to set it using a parameter named "missing". The new version changed the parameter name to "load_default".
I thought I had changed this parameter everywhere, but I overlooked that I use it a couple of different ways, which meant my search/replace didn't catch all of them. Apparently sending the old parameter name was not an error.
Without the right default behavior, missing fields defaulted to Python None / JSON null. Nothing that checked the "param.type" value to trigger special display behavior would match, well, ever. This broke display on nearly 8,000 powers that use "params" to identify powers executed, granted, given to pets, etc.
The fix has been uploaded and should be visible within 10 minutes of this post going up.

-
2
-
1
-
-
10 hours ago, BillyMailman said:
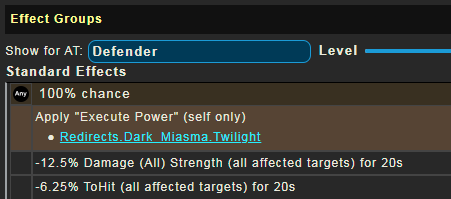
...of course, this is me, so I saw that because I was coming here with a bug report anyway. All versions of Twilight Grasp are failing to show what the Execute Power bit is executing, which they used to do at some point in the past. Poking around, it looks like it's every Execute Power, Fulcrum Shift is also failing to display properly.
Hopefully that won't be too hard to find the source of. Off the top of my head, that sounds like something I may have broken when I last touched the attribmod parsing back in April. Thanks as always for the report!
Edit: Hrm, nope, the logic is good, what's different is the data."params": { "type": null, "count": 1, "category_names": [], "powerset_names": [], "power_names": [ "Redirects.Dark_Miasma.Twilight" ] },
That "type" field should be "Power". I will have to go digging into the parser to figure out what's going on there. I have an idea where the issue is.
-
1
-
-
On 12/11/2021 at 5:52 AM, LQT said:
As of issue 27 page 3 attuned Air Burst IOs still do not give an option to convert by category.
This should not have been new to Page 3. This is a long-standing issue with how the conversion process works for Attuned IOs. The problem is that Attuned pieces count as their lowest available crafted level for conversion processing. Air Burst is the only Ranged AoE set that exists at level 10, so there's no way to convert it to any other set. That means the only option is to convert it to another Uncommon.
-
Current Alpha (Cryptic) data has been uploaded. If there's anything anyone wanted to check about stuff that's currently in testing, it should be there now.
-
1
-
-
So quick life update - I got married! This has been in the pipeline for a good year and a half, but we planned basically the whole thing ourselves so my free time the last couple of months has been spent getting everything ready for that. The dual good news is that it all went amazingly awesomely, and now I should have more time again for CoH and CoD.
My first order of business will be to get the latest Beta and Live builds out. That should happen tomorrow. Then I plan to get back into working some features I've wanted to work on forever, updating the site help, and publishing the JSON data maps (not necessarily in that order).
-
2
-
4
-
-
On 5/2/2022 at 5:48 PM, AlishaShatogi said:
The help pages appear to be broken (on Chrome? haven't tested other browsers).
Bah. I noticed that before and thought I had fixed it... Clearly not.
I believe it's fixed now. It loads for me currently in Chrome. I did have to force refresh my browser, but that was immediately after I made changes to the CDN configuration, so hopefully 10 minutes after I did that, everyone should see it no matter what.
-
Apologies if anyone hitting the site around mid-day today got broken pages. I added some increased site security settings that I had to then loosen since they initially broke a bunch of the site's functionality. Oops.
Tag me if you see any new breakage, as it's possible I overlooked something.
I'll likely clean up some of the things that broke today so that more strict rules can be (re)applied in the future, but that probably won't happen until I take the to revamp the site more thoroughly. I'm not talking about changes to how the site works for end users. This is more implementation-only stuff, like what version of Vue.js is used to render the dynamic content.
Suggested improvements or new features I haven't gotten to yet will still be a thing, of course.
-
1
-
-
lol. Called it! (That I'd break it.) Looking now.
Edit: Fixed 😅
-
Yep. Looks like it might not be trivial to add, as that attribmod has no special handling currently, and the attribmod handling code is a giant cascading if/else tree that I usually break when I touch, but it should definitely be doable and might not be hard.
Edit: Definitely not too hard.
-
1
-
-
Ended up running the extract last night and uploaded the data this morning.
-
2
-
-
I didn't expect these enemies to have new powers, or indeed to be new entities at all. I thought they pre-existed from last year.
I'll see if I can find anything new tomorrow.
-
On 3/21/2022 at 6:05 PM, Bionic_Flea said:
What if you reverse the polarity of the blilateral kelilactirals then route it through the Heisenberg compensators? That just might work!
Only if I can get it to 1.21 gigawats first. Or maybe 88 miles per hour. Or both...
-
2
-
-
Time for Uber's forum post book of the month.

Still not much progress on the data map. I hope to work on it later this week. But I did make some small, backend-only changes as an experiment.
Building all the CoD site data for one "version" of the game (Alpha or Live) takes a little over 8 minutes on the hardware I usually use. That's extracting everything, icons, data files, etc. but not including uploading it to where it's hosted, which can take a couple of minutes but is usually much faster because only changed files need to be uploaded.
When I build both Live and Alpha site data together, I build them both at the same time by running two copies of the program in parallel, one handling each build, so the time is about the same whether I build one or both.
As a reminder for context, CoD's data is pulled out of the game files using Rust code derived from that written by @RubyRed. This does all the low-level work of actually turning the very raw *.bin file data into data structures it can then pass around, manipulate, link together, etc. The Rust code handles this plus stitches powers into powersets and powersets into power categories ("powercats"), as well as things like figuring out which ATs use a power, plus a few more things.
At that point, the Rust code disgorges the extracted data into Python. This transfer about as efficient as it can be, as the Rust code is loaded into Python (and invoked) as though it were native Python code (just much faster). A final transformation of that data is done in actual Python code, turning all the raw data from Rust into dedicated Python objects (so there's an object type for a Powerset, a Power, an Atrribmod, etc.), then, slicing and dicing those into the JSON output used by the CoD website. I originally did this this way because it was easier for me to code the transformation in Python. That's because I'm very experienced with Python, and because Rust's design, which is meant to protect programmers from common coding/design mistakes, makes it hard(er) to do certain things that are easy in other languages. Or at least harder to think about doing them in new ways.
Anyway, the downside is that the bits done in Python are much slower than the stuff done in Rust. But there's a version of Python, called "PyPy", that's often way faster than the standard version. I wondered if PyPy could speed things up for me, at least a bit.
A speed improvement of 3-6 times is considered typical for PyPy. PyPy's is pretty darn compatible with regular Python, but the way it runs the code is very different than the standard Python interpreter. These differences aren't easy to summarize for non-programmers, but they tend to do two things for you: make the code just plain faster, and allow effective multi-threading. Regular Python supports multi-threaded programs, but the interpreter design hamstrings the ability of multiple threads to do really heavy duty work in parallel. PyPy doesn't have that problem.
My CoD Python code isn't multithreaded and really would not be easy to make it so, but I still wondered if PyPy still shave off some execution time if I just dropped my code on it mostly as-is.
So I spent some time today figuring out how to get the Rust/Python library to play nice with PyPy. This mostly involved upgrading a few things in the project and then fixing a few things that this broke. Getting everything working with PyPy actually wasn't very hard, but I did spent a couple of hours stumbling over a couple of issues that were actually quite simple in the end but just weren't document well.
So what happened?
The PyPy version actually took about 30 seconds longer to run. Oops.

Why? Well, based on watching the system while it ran, and knowing a little about how PyPy works, I think the problem is that what my program is doing is kind of a bad deal for PyPy. To explain why, I have to go a little into the territory I said would be hard to summarize. Programming runtimes need to deal with things, like variables or data structures, that a program was using but is now done with. If it doesn't, the program will just fill up memory with unused junk until it runs out of places to put things. There are, broadly, three ways to handle this problem:
- Make the programmer responsible for cleaning up after themselves. You ask for it, you have to explicitly clean it up when you're done with it. This is, except in the case of extremely low-level, high performance code, not that common in modern languages. (Note: CoH's client and engine code, written in C, works this way.) The historic problem with this approach is that it is easy to get wrong and create not just memory leaks, but situations where you trying to use memory that's not yours to use any more. (This is the source of whole range of security vulnerabilities in the real world.)
- The language or runtime automatically cleans up things that are not used any more as soon as this becomes "obvious". There are a lot of ways compilers or runtimes can tell when a variable (and/or what it pointed to) is no longer used, and whatever it pointed to can then be cleaned up on the spot. For the most part, this is the approach taken by regular Python. It's convenient and relatively easy to design, but does have some performance implications and sometimes needs some help from a garbage collector anyway (see next point) so it's not always preferred.
- Create a "garbage collection" mechanism. Basically, these languages figure out when something is unused after the fact, sometimes using very complicated analysis of what's in memory. Stuff that's been marked "old enough" is slated for cleanup by a reaper that runs in its own thread(s), so that, in theory, cleanup of unused stuff doesn't steal any time from the main program. This is the approach taken by PyPy's version of Python, as well as well-known languages like Java, C# and Go.
It turns out that PyPy's "garbage collector" expects most things a program uses to stick around for a while. A program that creates tons of transient objects and then rapidly discards them (which CoD's Python code definitely does) breaks PyPy's tuning assumptions, leading to a buildup of junk that isn't cleared out as fast as it could be. I think PyPy actually would have run a little faster than my code, except near the end it used a ton more memory than the regular Python version. This caused the VM it ran it in to use swap memory, slowing down its performance.
There's another reason, though. I already do most of the heavy lifting in my code in other, faster languages, rather than pure Python. I already talked about how a lot of the CoH data parsing is done in Rust. I also use a very fast Python library written in C++ to write out the JSON data. The three things the program really does is load the data, turn it into Python objects, and save those objects as JSON. The first and third things probably can't get much faster. That leaves turning the data into Python objects, and this is the place where tons of temporary objects get created and discarded.
I could speed up my extract code by stripping out the step that turns the raw data spit out by Rust into Python objects. That step is not strictly needed to emit the CoD data JSON. If that was removed, the code would basically be a variation on Ruby's tool. I suspect it would shave a good 3-4 minutes off the run time. But the Python transformation step gives me something that I can dump out and easily load back into an interactive Python interpreter later, and this is much easier (and faster) to work with than the final JSON. I use this setup all the time to find answers to questions for things you can't find on CoD itself, or would be very hard to generate. A semi-common example is to spit out a report like "what powers use attribmod X?") Adding 3-4 mins to my build time whenever there's a new CoH release is worth it if it does something that saves me tons of time every time I want to access the data.
This just shows that what's "best" (let alone "fastest") in a given scenario is highly dependent on use cases.
-
1
-
 1
1
-
1
-
Not much new progress yet, but letting y'all know I haven't re-vanished. Still plenty of real-life stuff keeping my hobby coding time low for now.

-
1
-
1
-
-
Working on a data map makes clear I don't have explanations for all the struct fields. I'll need to go through and add (and in some cases, dig up) explanations for them. It's not a ton, but it's more than I want to leave unexplained, if I can avoid it.
Edit: OK, this is done. All the fields for all the Rust data structures (what gets turned into the "raw data") have doc comments that explain them to the best of my knowledge. Now I just need to turn that into something I can shove into the site and archives.
-
1
-
-
Thanks for the offers of assistance, gang. I think if I need help with paying for this I'm in deep trouble and would probably need help with other things first, so I am not expecting it, but I still appreciate it.
I just uploaded a couple of minor tweaks.
- The raw data archive filename is now dependent on the data set viewed on the current page. For "live" data it's called "raw_data_homecoming.zip" and for "alpha" data, it's "raw_data_cryptic.zip". Those names align with the "revision" name up in the top right of the site ("Homecoming_xxx" for live and "Cryptic_xxx" for alpha), because those are the "internal" data set names I produce.
- I discovered that, at least on some browsers, the vertical scrollbar could flicker on and off rapidly during dynamic page changes, like the main "hamburger" menu fly-out when clicked, or while the "busy" icon was spinning. This only happens at some window sizes, so I'm guessing some people never see this, even on browsers subject to it. Anyway, there is scrollbar style that avoids this effect, and I added it to the site's styling. The vertical scrollbar is now an "overlay" scrollbar, meaning it appears on top of content when it's visible, rather than taking up some of the space on the side of the page.
-
So a long-ago requested feature is now live.
This lets you download a zip archive containing the "raw" JSON representing the data that comes out of the Rust library, before I do any additional massaging of it as used in the CoD site. Right now this file is about 83MB.
This is really only helpful for either tool makers, like folks working on something like Mid's, or for the terminally curious. The data in the archive is pretty close to what Ruby's powers project code would emit in "raw data" mode. My code has diverged from Ruby's, but the basics are still very close.
I took some time today to make sure the Rust side doesn't export things that are not "actual" powers data info. This means book-keeping fields added to powers/powersets/powercats that are used while doing things like building power/AT relationships. They aren't actually used any other way, so they always should have been filtered out anyway.
Right now there's no "data map" explaining what all the fields are. That might take a while to produce, but the good news is that the Rust code's own comments can be used to automatically generate most of it. I plan to work on this later this week, and to add it to either the site help, in the archive, or both.
PS: If you switch to the Alpha data, you'll get that server's data. The file name is the same either way, currently (I may change that), so be sure to rename it if you download both.(Fixed. See my next post below.)-
4
-
-
14 hours ago, Uun said:
Don't get old?
Doing my best without considering any extreme measures. 


City of Data v2.0
in Tools, Utilities & Downloads
Posted
I don't think displaying the end cost / time of toggles is a bad idea, but I definitely wouldn't replace the existing info. I'd probably add a derived "endurance burn" value somewhere that only appeared for toggles.