_NOPE_
-
Posts
2543 -
Joined
-
Days Won
7
Content Type
Profiles
Forums
Events
Store
Articles
Patch Notes
Everything posted by _NOPE_
-
It wasn't "compacted", not at all. The difficulty was... well, read this and you might understand: https://iipc.github.io/warc-specifications/specifications/warc-format/warc-1.0/ Add to this the fact that the internet archive added their very own HTTP header on TOP of the warc format, and it became... challenging... to parse it properly and accurately. Add to THAT the fact that these large files had to be parsed as a continuous stream, rather than all at once as I did with all the rest of the files, and I hope you can understand the challenges.
-
I was able to "extract" the files from the largest WARC file - however, the images aren't showing properly, so I have an error to troubleshoot. In other news, all OTHER files can now be browsed at http://cohforums.cityofplayers.com/files/ Almost the entire forum is there... it's now just a matter of making it searchable!
-
I've written my method today to attempt to extract all of the data from the ten largest WARC files, by doing the following: Opening the file via a StreamReader, and reading it line by line, rather than all at once. When I come across a line that doesn't start with "WARC/" (the new record identifier), I'm just adding the line to a Stringbuilder that's accumulating the lines found thus far. When I DO come across a new record marker, I dump the Stringbuilder to a sequentially numbered file, and start a new one. I also add it to a list of files to process further When I'm done "splitting" the WARC file into sub-files, then I'm going to go through that list of files using the same methods that everyone was using to help me extract the source files. I just ran this on the first large file, and... holy buckets! It contained over 70,000 WARC records in that one file! This.... could take a while. 😮

-
Thanks for notifying me. I've removed the link from 10 months ago. You can install the map pack through the main program's interface, no external files needed: http://www.cityofplayers.com/coh-modder/
-
A fascinating discussion that has taken place over two years on a fix for this: https://github.com/dotnet/runtime/issues/12221 A lot of people WAY smarter than me thinking ALOT about this.
-
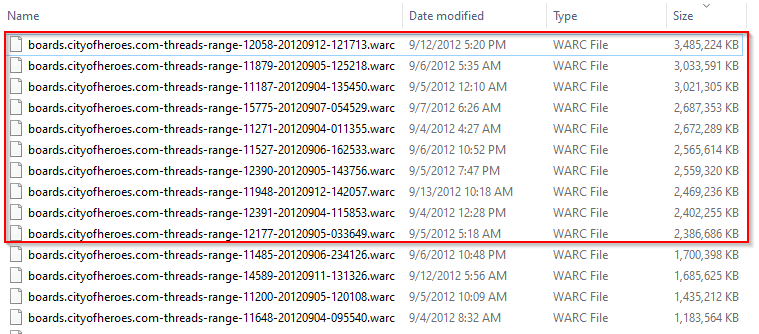
Alright, so those last ten files that failed, were also the ten largest files, no surprise. They failed, because they are larger than 2GB big. "Ahhh", says a wizened and experienced programmer, "you must have just faced the 32 bit limitation! Just recompile and run the program in 64 bit!" Normally, yes, you'd be right, Chuckles. But not this time. I've been reading the files byte by byte, and putting them into a byte array for processing. And, sadly, a bye array, in fact an array of ANY object is limited by the definition of an array itself, which is defined by... dun dun DUNNNNNNN..... the int32 numerical type. Which... is limited to 2 GB. https://docs.microsoft.com/en-us/dotnet/api/system.array.length?view=net-5.0 I have to think of another approach to handle these larger, probably more important, files. And I think I have an idea, relating to using a constant stream to split the file into smaller chunks by using the WARC header marker as a delimiter. But that will have to wait until Monday at least.
-
Project Update: Thanks to everyone's help (mostly @WanderingAries I suspect, but thank you everyone!), all files have now gone through the first phase of the process, where the WARC data is extracted from the WARC files, and into the original files. There were however, a few exceptions that I will need to look at manually - files that ended up being completely empty on output (with the exception of the "credit" file that I'm generating for each zip): Also, there may be SOME files that didn't get zipped properly, and I'll only know this after I go through the 12,710 files and try to extract them one at a time to my local PC. I'm going to automate this process on my end, and keep a log of all files that fail to extract, then investigate those. I will let the community know when and if I need assistance with further phases of the project, but for the meantime, I'm probably going to "go dark" for a while while I work on this, as there won't be anything useful to report. Thank you again to everyone for your assistance, that was a HUGE accomplishment, just getting those original files extracted. Now the next steps are to figure out what to DO with those files. As I've said before, but I'll repeat it here, here's the rest of my plan, in a bit more detail: Validate the veracity of the data (what I mentioned above with the "exception" files) and correct any errors Determine the appropriate file structure - if these can all just be dumped into one folder, or if that'll cause errors just due to the massive number of files - they may need to each be placed in a separate folder to stand on their own separately, and then linked appropriately. Standardize all of the file names, then standardize URL references to those files to match the local filenames (this step may require more borrowed processing time once I know I have a working process!). This may require having an algorithm perform a "search" for the appropriately named file in the local system amongst many subdirectories (as mentioned in step 2 above). Submit all of this to Google to determine if they can index them If Google can't then I'll have to create my own method/algorithm for searching these files. So, please sit tight, this... could take a while. Plus, I've still got my day job that, you know, pays me money... so I gotta give them some time too. 😛
-
Let me just handle the final few, alright?
-
Probably because it's already there... are you still running multiple instances???
-
Go ahead and try again. There were duplicates in both directories, not sure how that happened. But should be fixed now. May happen with the other files.
-
They're stuck. I just unstuck them. Do one at a time now. If they still stick, I got stuff to look at.
-
-
Sorry to get your hopes up, but I just pushed the 32 files that were "stuck" in processing back to input. We can see if they'll process the second time. If not, I need to look at whatever errors are generated.
-
1.6 is now available for download with (sort of) "large file support". Also, if a file errors, it now automatically deletes the local WARC file, so that you don't have to.
-
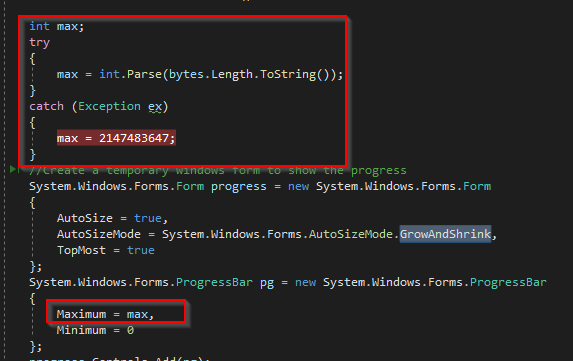
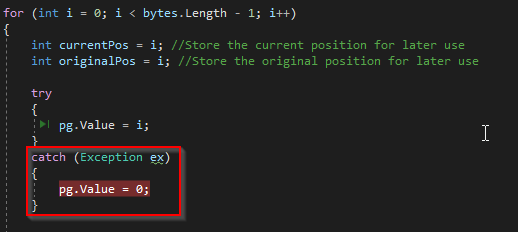
THIS one is actually kind of an interesting and cool error, well at least to me because I'm a dork. It's erroring out at this point in code, when I'm trying to instantiate the ProgressBar to show you the progress of the FTP download: Well, the "Maximum", "Minimum", and "Value" properties of a ProgressBar object are all int32s. int32s have a maximum allowable value of 2147483647 as per Microsoft. So that means a progress bar can't handle any numerical values higher than that. And when I'm making these bars, I'm setting the max value to the total number of bytes for the file. Do you see where I'm going with this? The 10 largest WARC files will OVERLOAD the maximum allowable values for a ProgressBar's int32 values: So, since it's only 10 files that are going to have problems with this.... I'm going to "cheat", and... do this: And this.... Basically just set the max of the bar to the max of an int32, and when it comes time to set the VALUE of the bar to higher than that, just reset it to 0. So, the bar will go back to empty and start filling again. It sucks, but it's only informational, so at least you'll still see that progress is happening, even though the bar's length won't be accurate. Sorry. I'll release that in v 1.6 after ensuring that the new code works with this specific file without issue.
-
Same concurrency issue. (Seeing a trend?)
-
Same concurrency issue, just happening at a different part of the process. You're just trying to do too much at once on the same PC dude! 😛
-
Another concurrency issue, but probably a rare one. I'm not going to deal with this one... basically two of your clients on the same PC tried to process the same file at the same time. I expect every random file to only be attempted to be processed once by a single PC... your 50,000 processors running at once caused this 😛 . When we get near the end of it, when there's like a dozen files left, we'll most likely have to make sure each PC is only processing one file at a time.
-
This error was caused by DIS FAWKING GUY: http_www5.snapfish.com_snapfish_viewsharedphoto_p15541346791138707_l6004733025_g4695186025_cobrandOid1000_campaignNameShareeNewReg_30FreePrints_2010Feb_otscSYE_otsiSPNRjsessionid7F5840A943EB6DAC642E8E3707FFDE14 Completely f***ing with my "SanitizeFileName" method, because of the .com followed by the super long freaking string afterwards. My method didn't know what to do with such a long "extension". So, I "hacked" the problem by truncating any extensions longer than 3 characters to just 3 characters long (but only when the filename with it would be over 250 characters. So that monster file now becomes this: "http_www5.snapfish.com" whether it likes it or not... because that file is an asshole:
-
I come back from the vacation weekend and.... HOLY CRAP PEOPLE, good job! Now I gotta up my game and get the other phases figured out... I'll look into errors mentioned above. Thanks @WanderingAries
-
Just the different types of errors. Each error SHOULD have the filename listed, right? I can use that file as a sample to debug the issue. No need for duplicate files with the same problem. And as for what failed on my end? Thats what the stack trace is for. 😉
-
Yuppers
-
With it being caused by FTP Download, there's only one explanation- it's one if those 45 files that got moved from processing to input. Sorry. I suggest opening your temp folder and deleting any WARC files there that aren't currently being processed.
-
@WanderingAries, as I mentioned before, maximum path limit is 260 characters, filename and path all included. There is no specific filename limit except where it makes the path linger than 260 characters: https://docs.microsoft.com/en-us/windows/win32/fileio/maximum-file-path-limitation?tabs=cmd
-
FYI, since we had 45 files stuck in "processing", I moved them all back to the input. This MAY have caused some issues for your currently running processes. If it did, just restart those instances, and it should continue from there. Maybe clear out your temp files first, but that's not necessary. I just thought I should "clean those up" before I left for the weekend.