_NOPE_
-
Posts
2543 -
Joined
-
Days Won
7
Content Type
Profiles
Forums
Events
Store
Articles
Patch Notes
Everything posted by _NOPE_
-
While this is fascinating and all... here's an update on Project Spelunker. I got the hard drive a couple days ago, and installed it, installing a fresh copy of Windows 10 on top of it (my original HDD is still installed as a backup "just in case"). Man, this thing is so much faster and QUIETER than my original! Anyways, I've reworked the code to improve the GetSanitizedFileName method to make all file name "web acceptable", because I noticed that a few of the files when you attempt to click on them on my server, failed to load because the filename wasn't recognizable as a valid name by the server. Also, I removed the extra HTTP header checksum that was showing up on HTML/PHP pages, so those two random alphanumeric chars won't show up at the start of every webpage now. I also checked out Google after requesting a site index of the site, and realized that Google apparently can't index a site that doesn't contain a "site map" page that has links to all of the other files - apparently as smart as their algorithms are... they haven't figured out how to index a directory listing from the server. Weird. So, I installed HTML Agility Pack and used it to create an "index.html" page, and now every time my WARC script processes a WARC record, not only does it create the file, but it also creates a relative path link to the file and inserts it into the index.html file. This should serve to create a site map for the entire old forums. Here's a screenshot of some of what it's done thus far: Hopefully Google can work with this and actually start indexing the site. I have two concerns right now: How BIG can I make an HTML page before Google starts ignoring it, or stops scanning the links in it? This page will end up containing literally millions of pages... Perhaps I'll need to break this up into multiple "index" pages and a master index page that references all the rest? I wonder if Google has documented somewhere its rules and limitations on what it will and will not index...? How will I possibly make this thing "crowd sourced"??? I'm not sure if it's possible, because I'd have to find some way to deal with concurrency issues... with multiple people trying to update the index document at the same time.... I don't know if that's possible. Thinking out loud right now... perhaps I've got this wrong. Perhaps instead of making the index document "on the fly", I should create it at the "end" of the project after all of the files have been processed. That may work better. However, there's something to having a visible product as a result of your work.... I'm torn.... it's already taken this long, what's a bit longer? I could fairly easily crowd source the extraction of the WARC files up to my server, I think, and not have to deal with any concurrency issues, as I'll have the code search an "unfinished" directory for all unprocessed WARCS, then a "processing" directory for all WARCS that others are processing, as well as a "processed" directory to place all WARC files that have already been processed. Add to that a randomizer to have each person pull a new random file every time that hasn't been processed, and it should be null sweat to get that part done. But what say you all? If I "crowd source" the processing of these files, like I tried to do the last time with my failed database solution, would you be okay with not being able to see the results of your actual efforts until at the end of the project? I mean, you'd at least be able to see how many WARCs have not been processed, are being actively processed, and have been processed... would that be sufficient as a progress indicator for the work of the community? The project failed the last time because of issues with trying to pump too much data into the database. Well, we're not doing a database this time, just a folder with a shit ton of files. And rather than pushing the final results up to a web server, I could have your client programs connect to my PC directly (output only of course) and write the files to my hard drive. Then, after everything's been processed, there would always be a "backup copy" on my hard drive, in case my ISP has issues with the sheet amount of files we're uploading.... So many things to think about...

-
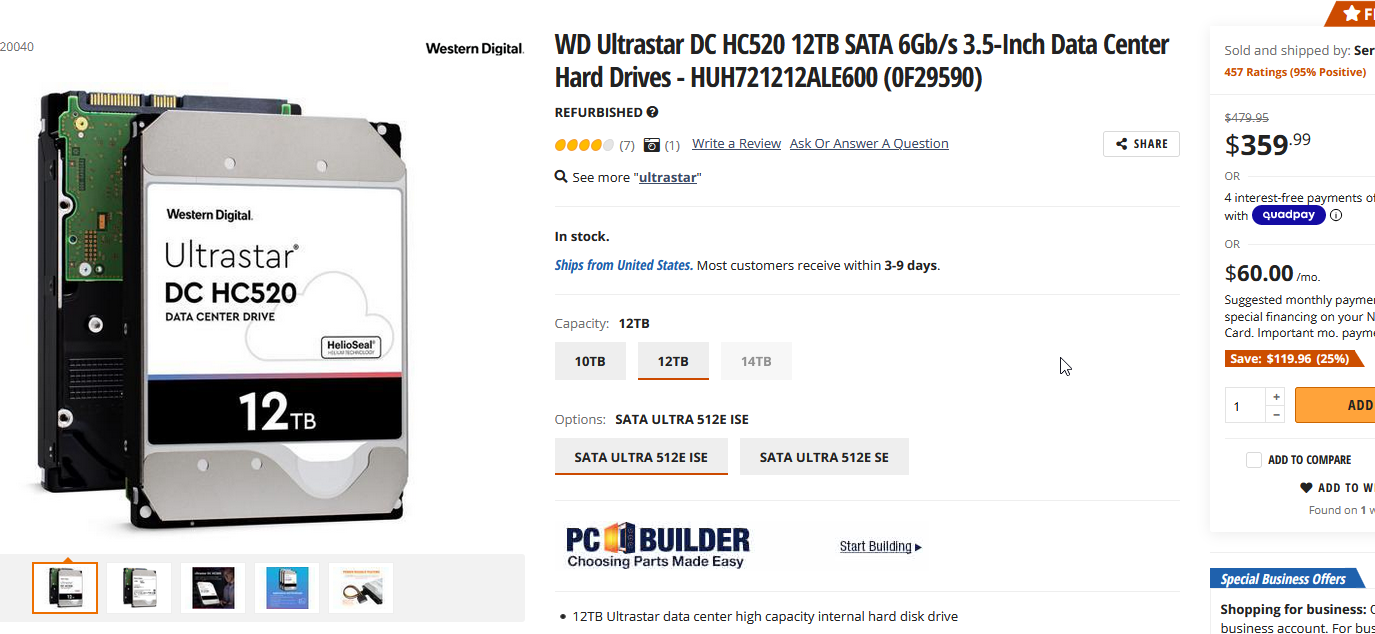
I got this sucker coming on Friday - about 75% of the storage space as the one in your link, for about half the price as that one - seems a fair deal:
-
I might have to consider something like that @WanderingAries, my system seems to be super slow for what I'm trying to accomplish. However, I think it may also be more efficient to extract the files, transfer them to the server, and then delete the original source files when there's a successful transfer. That way, there's less files just sitting around doing nothing. I may also "crowdsource" this like I tried to do last time with the database solution that failed. By the way, in the meantime, I'm still uploading what I have so far, over a million files and still copying:
-
Solarverse's SFX Consolidated List of Mods
_NOPE_ replied to Solarverse's topic in Tools, Utilities & Downloads
Not sure what you mean by conflict. If you mean two mods affect the same files, then sure of course thst can happen, but it shouldn't break anything or cause errors. The second sound file will just replace the first, and the user can know that if they wish by reading the XML file inside the mod. I don't think it behooves mod authors to investigate ALL other mods to see if any other mods MIGHT conflict with theirs. That's just... kind of ridiculous if you ask me. -
Solarverse's SFX Consolidated List of Mods
_NOPE_ replied to Solarverse's topic in Tools, Utilities & Downloads
I'm more curious to see if the issue can be produced at-will. Because if someone can do that, then I can fix the bug. I'd rather fix the bug than have to have "warnings" on mods. Because obviously it's a bug in my code somewhere that caused that issue, but it's the only time I've heard of it. -
So.... good news/bad news. The bad news is, yes, my system restarted for an automatic update. The good news is, a whole lot of files got extracted before that, so while I reconsider my code and recode it to make it a more sustainable process, I'm also in the process of copying what I HAVE extracted so far over to http://oldcohforums.cityofplayers.com/ So now you can at least get a "taste" of what I've "scavenged" so far. There's THOUSANDS of files, and frankly, my computer may not have the storage capacity to hold them all and keep processing in the same directory without breaking... so, I'm reconsidering how I process these. I may have to make a subfolder for each one of the WARC files, so that everything's not just in one GIANT folder... I'll have to think on this for a bit. I've also got to figure out if Google can just start indexing these things, or if I have to do anything special to make it index them. Otherwise, it's just a bunch of loose files sitting in a directory, and finding the content that you want would be like a needle in a haystack! More to come... Soon™.
-
So.... uh.... slight update. Remember how it looked Ike I was almost half done? Yeah, it started slowing down... ALOT. I couldn't figure out why, but then I remembered that I had pre-sorted the file list from smallest to largest. So.... we're probably not even 25% done yet.... sorry. 😪
-
FYI, still chugging along. Not quite halfway there, but I would have expected any major errors to have happened by now: Now, cross my fingers that some app on my computer doesn't decide to perform an unattended "update and restart" without my permission!
-
spreadsheet/dataset of all powers, range, recast, etc.?
_NOPE_ replied to malleable1's topic in Tools, Utilities & Downloads
It should be noted that my program was based on data from the original SCoRE leak.... so any changes that HC has made to the powers since then would NOT be reflected in that data. If anyone has the time to make a proper and full DeBinner, then we could use that to obtain updated data from the client files. But, until then... this is what we got. -
So, I'm about 20% done processing, I'd say the initial processing should be done in about a week, assuming nothing interrupts the process: And so far, with that 20% processed, I have this many files so far extracted from the WARCs (with my own WARC parser that I built from the ground up): So, with 20% being 579,873 files taking up 39.745 GB, I estimate that the final total will be about 2,899,365 files taking up roughly 198.728 GB of space. Now, that's just raw, unprocessed files, written directly from a bytestream. But they'll be out there in file format, and I'll stick them in a web directory and make it searchable by Google, so that's something. The unfortunate thing is that since I started this in Debug mode, if anything "breaks", I have to start over. But I'm going to take that risk. It's been a few years, what's another couple of weeks? The second step will be to ATTEMPT to replace all of the internal URLs (those pointing to boards.cityofheroes.com) with relative path URLs that link correctly to the appropriate internal documents. Now, to get the correct filename to replace it with should be easy, because I had already written a "GenerateSanitizedFileName" method that allowed me to turn all of the return URIs into the files' final filenames, so I can just pass the references to that. The trick will be for me to learn enough about the HTML Agility pack to make the swap and replace happen, and I'm not sure how much processing time that whole process will take, given the number of files. While Step 1 here I consider to be reasonable enough to just run on my PC, for step 2, I might have to make a "mini-app" and actually try to resurrect "Project Spelunker" and ask others for their assistance with processing these files. We'll see how that goes. The third step will be to attempt to correct for any encoding errors. I already notice that a few of the image files won't work because of corruption (most work though), and a few of the HTML files appear to have a couple of extra digits at the very start of them. Not sure what that is, maybe a "checksum" value or something, but I'd like to strip those off if I can figure it out. We'll have to wait and see how this all pans out. Time will tell.
-
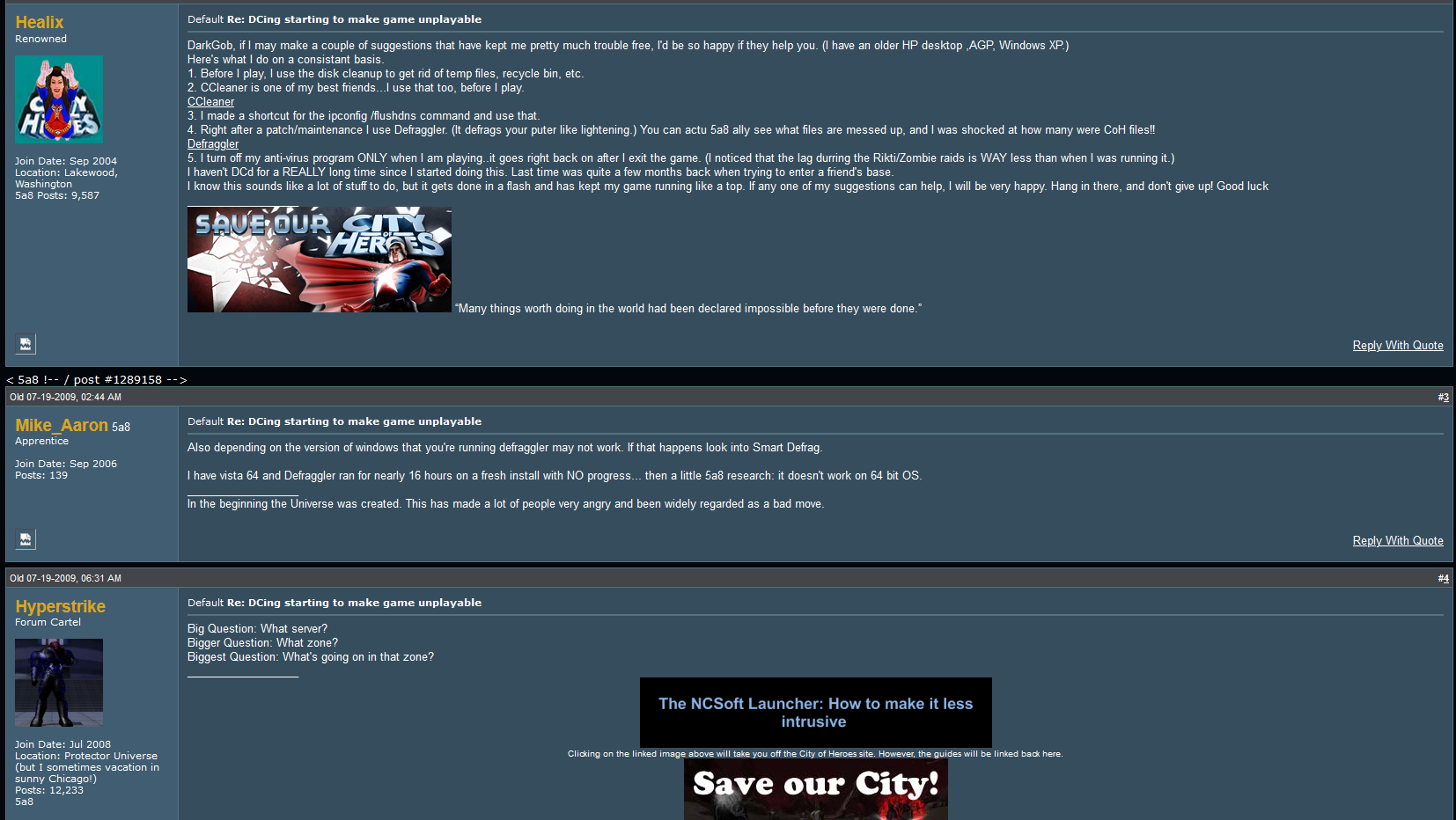
Progress is slow and steady, but this is just phase 1: Here's some interesting things that I've found so far: With a special appearance by @Healix and @Hyperstrike:
-
It has begun...
-
I'll have to think on this @Sarrate, it's a good idea. I think what I'd have to do is keep a "historical record" of the files, and what order they were modded in, and then when you went to uninstall a mod, try to figure out which "version" of each modded file should be restored based on that. It would take some work, but I'm sure it's possible. I'd just have to think about HOW exactly I'd do it. My source code is out there and free to modify, if you've got the time and want to think about tackling it for yourself. You'd just have to setup your own FTP server for testing, as the credentials to mine I have removed from the code for obvious reasons. Its in c#. 😃
-
I think this could work, actually. What I suspect is that not all of the sounds are at appropriate volume levels for the type of sound that they are. "localized sounds" (sounds that travel "with you", like your powers), should be at a different level than "ambient sounds", and BOTH categories of sounds should be "normalized" to have the same maximum and minimum "peaks and valleys" (dBs). I wonder if anyone has ever taken all of the sound files in the game, ran them all through a program like Audacity, pulled out their peak, minimal, and average decibal levels and put them all on a spreadsheet to compare them. Or has sound design in the game always just been "slap-dash"? Hmmmmm.....
-
Not really at this time.... the closest thing that it has is whenever a mod is installed, if any existing files are there, they are automatically backed up, and then restored once the mod is uninstalled. So, lets say you have Mod 1, which affects Wolf sounds, and then Mod 2 affects ALL animal sounds. Once you install Mod 2 "on top of" Mod 1, then wolf sounds will be "backed up", and then when Mod 2 is uninstalled, you'll be back to the wolf sounds from Mod 1. I had a hell of a time figuring that one out already, I can't imagine trying to figure out anything more complex than that!
-
Since @AboveTheChemist reminded me that this program exists, I jumped back into the code. I just pushed out a new update on the website now, version 1.69 (heh). The only additions to this are an upload progress bar, as I just noticed that while downloads have a progress bar, uploads didn't. That is all at this time. Please let me know if you see any other way the program can be improved.
-
FIRST! 😛
-
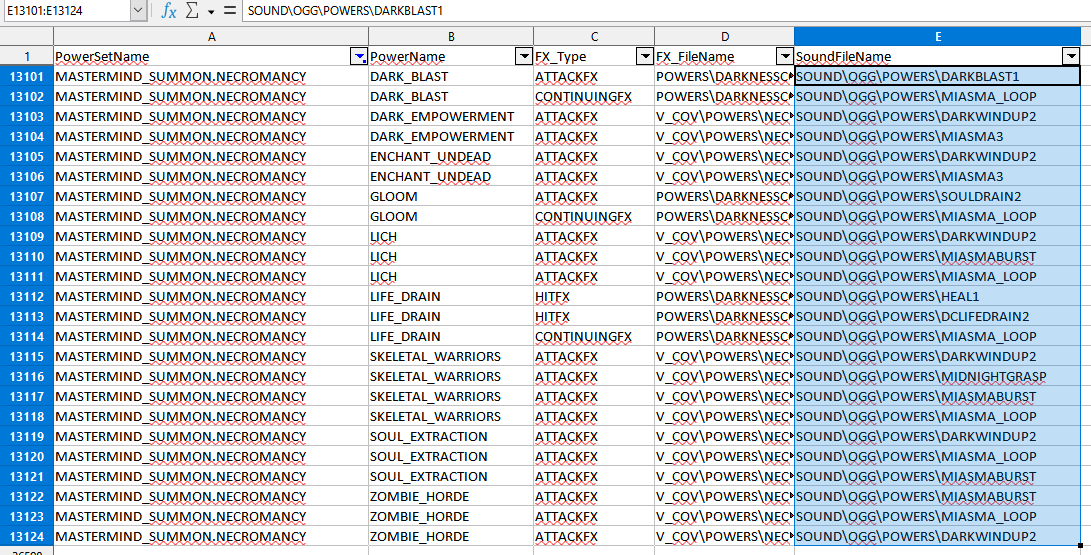
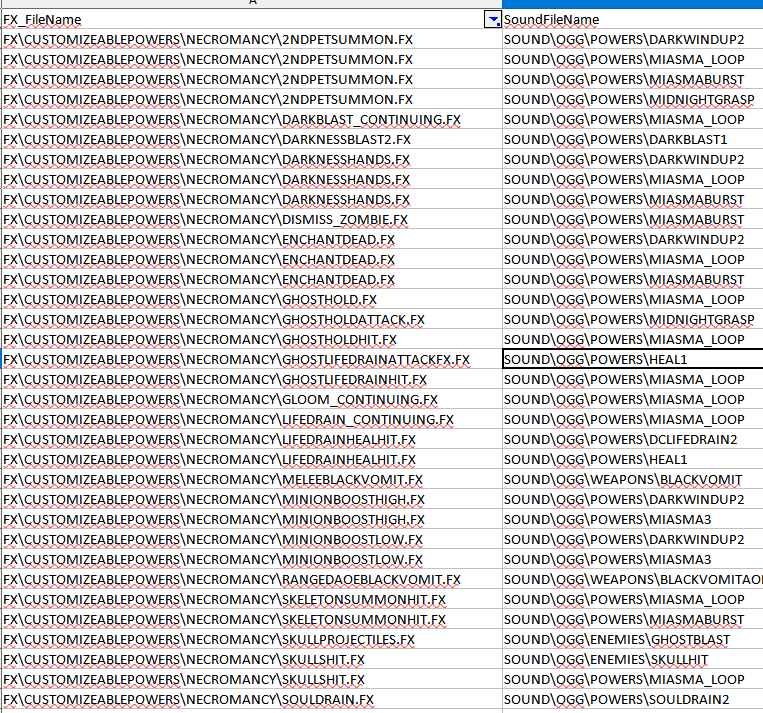
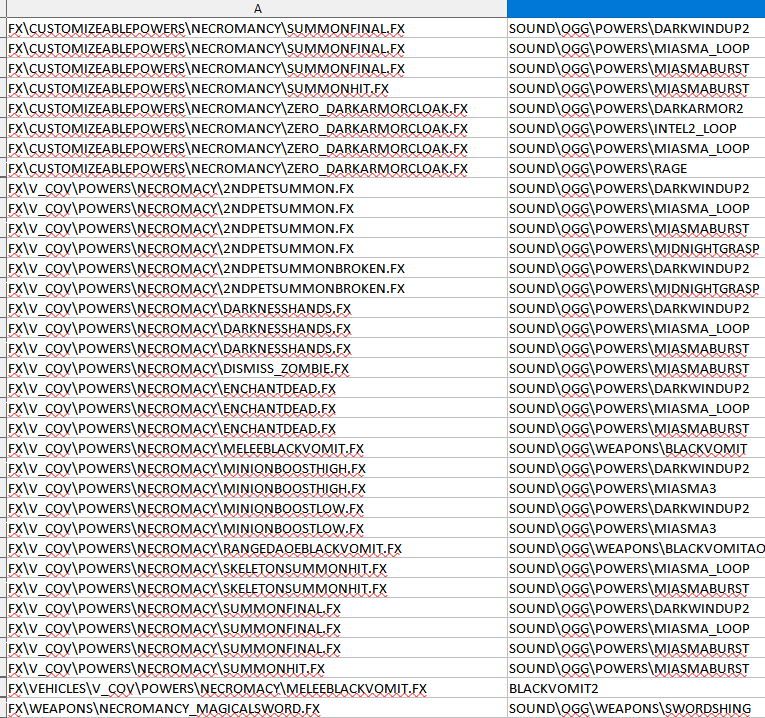
Here's the necromancy powers sounds: Here's the pet sounds (from what I can see): One of them should do it.
-
VidiotMaps for Issue 24 and Beyond
_NOPE_ replied to Blondeshell's topic in Tools, Utilities & Downloads
Now, why would a simple boolean value EVER cause any issues???
-
VidiotMaps for Issue 24 and Beyond
_NOPE_ replied to Blondeshell's topic in Tools, Utilities & Downloads
@AboveTheChemist and if you want to update the main Map Pack in Modder with the updated maps once you confirm they work, go nuts. Or I can do it if you want. -
Always love me some Monty Python. The Modder was written in C# using the .Net Framework in Visual Studio, all Micro$oft creations. So, getting it to work at all outside of a Windows environment? All I can say is, you'd have better luck facing the Black Beast of Aaaaaaaaargh.... or a killer rabbit. Or even a French Taunter.
-
VidiotMaps for Issue 24 and Beyond
_NOPE_ replied to Blondeshell's topic in Tools, Utilities & Downloads
@AboveTheChemist for whatevewhat's worth, the DeTexturizer is SUPER easy to use, it works basically like WinZip, bit with a simpler interface. -
VidiotMaps for Issue 24 and Beyond
_NOPE_ replied to Blondeshell's topic in Tools, Utilities & Downloads
That's a really good idea. I'll look into the original texture files when I get the time. I didn't think of that. That might have some answers. -
Its available, you just have to join the group to download it. I don't know why they made it that way.
-
@Lightyears did you check the Rosetta Stone?