Telephone
-
Posts
153 -
Joined
-
Last visited
-
Days Won
1
Content Type
Profiles
Forums
Events
Store
Articles
Patch Notes
Everything posted by Telephone
-
Hello! I'm Telephone, and you may remember me from previous technical posts such as As many of you are likely aware, performance on Excelsior during peak times has been less than optimal for some time, and the recent increased player count since the license announcement has not improved things. We've spent a lot of time over the last couple of years profiling the shards and even more over the last couple of weeks in an attempt to resolve the performance issues, but we're now at a point where we need to actually upgrade our hardware, or, to be more specific, our SQL host hardware. The SQL Queue The issues we are encountering are caused by what the City of Heroes™ server software calls the SQL Queue. Everything players do is ultimately committed to a back-end database. Under normal operation, most of these operations are both parallelized and asynchronous, and they commit quickly (within nanoseconds), but there are some operations which are much larger and take more time to perform. There are also certain operations which have stricter timing requirements to maintain database integrity; these operations often come with what is called a barrier. When a barrier occurs, the entire SQL queue must be drained before continuing, meaning our normal large pool of asynchronous operations has to stop and wait on the barrier. One of the biggest barrier culprits (until a very recent fix by @Number Six) was the disbanding of a large league, which is why you may have noticed at the end of a Hamidon raid the shard often seemed to lag for some time when the league was disbanded. While we were able to find a solution to this barrier issue, there are other operations where the barrier can't be removed without significant rearchitecting. When the shard is very busy and there are a lot of other large operations taking place, a barrier can cause the entire shard to lag for several seconds, and this often gets into a vicious cycle where some of those other large operations may have their own barrier, or there may be database conflicts and the entire SQL operation is rolled back, rebuilt by the server, and sent to the database again with another barrier. The queue does eventually drain, but it could be a period of many seconds or even minutes until everything finally unwinds. If it gets particularly bad, the shard may enter what's called Overload Protection, where (among other load-shedding measures) new logins are temporarily forced to queue, even though the shard has not reached its player limit. Throw More Hardware At It Homecoming has been in operation for nearly five years now, and in that time the size of our databases and their indices has grown significantly. Our existing primary North America SQL hosts (of which we have two) are legacy OVH Advance-3 servers, with Xeon D-2141 CPUs (8 cores, 16 threads, 2.2-2.7 GHz), 64 GiB of RAM, and two NVMe drives (in a mirrored configuration). Excelsior's database alone is over 100 GB in size, and during peak time sees many thousands of transactions per second, so we have simply outgrown the hardware we have been running on. We're planning to upgrade both of them to the newest iteration of the OVH Advance-3, which is a Ryzen 5900X (12 cores, 24 threads, 3.8-4.7 GHz), 128 GiB of RAM, and four NVMe drives (in a RAID10 configuration). The main benefits we expect are that the doubling of RAM will hold many more indices in memory, and moving to four drives instead of two will double our I/O capacity. We're upgrading the one Excelsior (and Everlasting) are on first, and if that works well we will upgrade the other one (hosting Torchbearer, Indomitable, and global services) next month. Power Underwhelming? It's possible (but unlikely) that even this upgrade would not be enough to resolve the issues on Excelsior. The most likely cause of this would be insufficient RAM; the newest model of OVH Advance-3 has a maximum of 128 GiB of RAM, so we would need to go up to an Advance-4 to get more RAM (this would also increase the number of cores, but at a lower clock speed). This would be a somewhat significant cost increase, but if it becomes necessary we will explore it. There's also the possibility that the issue can't be resolved by more hardware; some of the SQL Queue problems are fundamental to the system design. We haven't stopped looking at fixes from the software side and while some of the barrier operations must remain barriers, there are potentially other fixes we can do to reduce load and database contention. TL;DR We believe our SQL hosts are no longer up to the task of handling our shards as they have grown, and need to upgrade their hardware. We're planning to spend approximately $600 this month and $600 next month in one-time charges on upgrading our primary North America SQL hosts. Our ongoing costs will increase by about $250-$300 per month ($125-$150 per month per database host; the amount is a little difficult to calculate due to taxes and SQL licensing costs).
- 83 replies
-
- 33
-

-

-

-

-

-

-

-
Thank you very much for the suggestion! Unfortunately, the way City of Heroes scales is not suitable for use with AWS GameLift. We can't simply start and stop mapserver hosts to scale with load, because scaling down would boot players off active map instances on those hosts (we can scale up relatively easily, however, though existing mapserver instances won't move to new hosts). In the very early days of Homecoming, we hosted on Digital Ocean and did some rudimentary scaling to help with load, but it was intensely manual and also resulted in booting players every time we scaled down. Other important factors include: The mapserver hosts make extensive use of shared memory and hence fewer, larger hosts are much more efficient than many small hosts. The absolute minimum memory to run a Homecoming mapserver host is 24GB. Our beta and prerelease mapserver hosts have 32GB each; the NA mapserver hosts have 192GB each (but could run with less); the EU mapserver host has 96GB. The mapserver hosts do need a significant amount of CPU. They need to run all the game calculations, enemy AI, pathing, and so on, as well as some of the physics simulation. The mapserver hosts run Windows. We actually use an older version of Windows on the mapserver hosts to save on per-core licensing; this would be less feasible on AWS. It is possible to run the mapserver hosts with WINE, but we haven't done this on anything like Homecoming's scale. AWS Dedicated Hosting Our three existing NA mapserver hosts are much more comparable to a c6a.12xlarge each ($1,340/mo Linux / $2,952/mo Windows). They're actually even more powerful, but assuming we were to make some compromises, we would probably end up going with the c6a.8xlarge ($893/mo Linux / $1,973/mo Windows). EBS would add another $10/mo. Each mapserver host also transfers approximately 5TB/mo to the Internet, which is another $450/mo. So not even including the rest of our cluster, the three NA mapserver hosts are already at between $4,059/mo (3 Linux 8x, and we'd have to run nested virtualization to use our existing Windows licenses, or swap to WINE-based mapservers) and $10,236/mo (3 Windows 12x). On top of this we'd need the rest of our cluster and then the SQL servers themselves. Even if we were to really grit our teeth and try to get a minimal AWS NA cluster, here's how it would probably pan out: - 3x Linux m6a.4xlarge mapserver hosts: $960/mo each including storage/bandwidth - $2,880/mo - 2x Linux m6a.2xlarge SQL Server Web hosts: $375/mo each including storage - $750/mo - 4x Linux m6a.large shard hosts: $80/mo including storage/bandwidth - $320/mo - 1x Linux m6a.2xlarge services host: $140/mo including storage - $140/mo - 1x Linux m6a.large auth host: $80/mo including storage/bandwidth - $80/mo The above comes out to $4,170/mo and doesn't include beta, GM support, developer support, forums, backups, CDN, security services, and a host of other things. It could possibly be pared down a bit more, but AWS (and most VPS providers) are just not geared towards our usage profile. HostHavoc I looked over HostHavoc's offerings, and it looks like their dedicated servers are almost all out of stock. I also didn't see a way to acquire SQL Server licensing through them (though they might offer that as a custom option). They also don't seem to have very much variety in available hardware (though we could certainly work with the offered Ryzen hosts). FragNet FragNet doesn't seem to offer dedicated servers yet, though they do say 'Coming Soon'. Other Options Just for completeness, there are other options out there. Hetzner is a competitor in OVH's space, but doesn't have quite the right mix of servers for our needs. OVH also offers some lower tiers of servers (Rise), but those don't have the vRack functionality or flexibility that the Advance/Scale lines offer. OVH has their own resellers as well (Kimsufi and SoYouStart), but they are even more limited than the Rise line and whatever hardware is available is limited to servers OVH has decommissioned from their main lines. Other VPS providers we could consider include Digital Ocean (as mentioned above, Homecoming was actually originally hosted there for a short while), Linode, and others. Most of them end up slightly to somewhat cheaper than AWS, but for our usage profile, we end up getting much less bang for our buck and still spending more than OVH. Thanks again!
- 25 replies
-
- 14
-
-
-
While I'm not quite as cool as Cipher, these may help answer your questions: https://forums.homecomingservers.com/topic/19636-june-2020-donations-finances/?do=findComment&comment=220949 https://forums.homecomingservers.com/topic/29090-mapserver-host-hardware-changes/ While there are many, many machines (VMs), we have ten physical hosts in NA right now: - Citadel (our bastion/security host) [OVH Advance-1] - Three SQL Server hosts (two production, one warm spare/backup target/management) [OVH Advance-3] - Three VM hosts (these host almost everything that's not a mapserver - the shard hosts, beta, prerelease, forums, development, build services, NA CDN, etc) [OVH Advance-4] - Three Mapserver Hosts [OVH SCALE-3] And three physical hosts in the EU: - Reunion (also hosts the EU CDN) [OVH Advance-1] - A SQL Server host for Reunion (also a remote backup target) [OVH STOR-2] - One Mapserver Host [OVH Advance-5]
-
 I look forward to Relentless Dr Q. And yes, we definitely know why not everyone plays on Brainstorm - fundamentally people like to feel like they've earned things. The difficulty of earning things is always a hard choice - but as other developers have mentioned in this thread, it's very likely the biggest fountain of Aether will be mission completions, so they will always be available, even if not at a guaranteed rate.
I look forward to Relentless Dr Q. And yes, we definitely know why not everyone plays on Brainstorm - fundamentally people like to feel like they've earned things. The difficulty of earning things is always a hard choice - but as other developers have mentioned in this thread, it's very likely the biggest fountain of Aether will be mission completions, so they will always be available, even if not at a guaranteed rate. -
There are approximately 700,000 characters in the level 1-5 bracket alone who have not logged in in the last 30 days (across all shards). Of those characters, approximately 600,000 haven't logged in in the last year. There's a significantly smaller number in the 6-49 bracket who haven't logged in in the last year but I don't have those statistics at the moment.
-
This has been updated on Brainstorm (and the patch notes have been updated). It didn't go out at exactly the same time as the patch because there needed to be a server configuration change. Level 1-5 characters will be flagged as inactive if they have not been played in the last 30 days. Level 6-49 characters will be flagged as inactive if they have not been played in the last 365 days. Level 50 characters will never be flagged as inactive.
-
Map Servered.. How many until calling it a day?
Telephone replied to Troo's topic in General Discussion
We believe the issue is mostly resolved - we're continuing to monitor and the graphs look much, much better than they were before. We still do occasionally see queue spikes, but nowhere near the duration or magnitude they were before. There are a few more server-side fixes that will be coming in when beta is promoted to live, but I don't have a timeframe on that yet. -
Just to follow up again (this will also be posted on Discord). Over the past few weeks during maintenances, we deployed multiple rounds of instrumentation and mitigations. We believe that the most recent round of mitigations has finally significantly ameliorated if not cured the issues seen on Excelsior. Among the large number of SQL Queue optimizations were significant fixes to performance issued caused by large team, league, and SG operations as well as corner cases encountered during certain character loading and saving operations. We also optimized the saving of certain temporary data to prevent it from requiring disk operations, and we found a few powers that were behaving very poorly and will be fixed in future patches. In addition, during the process we implemented a number of rate-limiting measures to reduce database load. One of these was a rate-limiter for Character Items. Note that even though Character Items shows up under the Email tab, it's actually a separate system with its own limitations. If you see the text 'Please wait a moment', your Character Items actions have been rate-limited to ensure server performance, and you can try again in a few moments. We're going to continue reviewing tickets, but if you've filed a ticket as I requested earlier in this thread, please follow up and see if your problem is related to Character Items (and if you're getting 'Please wait a moment' or some other error), or if it's related to the email system proper. If you're only receiving 'Please wait a moment' and then the problem goes away, or if the problem no longer occurs, please close your ticket. The AH is an entirely separate issue; it has its own rate-limiter (which is not new, and which has a different message) and is a known problematic system that we will continue to work to improve. Thanks again for your patience!
-
Just another brief followup that we're aware that the issues on Excelsior have been worse over the weekend. The bad news is we believe there may be an issue in the new instrumentation exacerbating the issue. The good news is we believe we might finally have discovered the root cause of the lag issue in the first place. I don't (yet) know if we'll be doing another instrumentation update during tomorrow's scheduled restart, but if necessary we'll do additional mid-week updates on Excelsior as needed with either instrumentation bug fixes or (ideally) a fix to the actual issue. For those of you who hunger for technical details, the current belief is that the issue is rooted in what are called 'queue barriers'. The SQL queue on each shard is actually processed by many parallel threads in the dbserver; operations relating to a particular entity are usually routed to the same thread to ensure ordering, but sometimes certain operations require additional synchronization (for example, multiple entities might be involved) and barriers are used to provide this synchronization.
-
Just to provide a quick update: Last maintenance (not today's) we rebuilt the SQL indices for all shards and global services. While this did have some benefits, it didn't give us the improvement we were seeking nor resolve the issues seen on Excelsior. Over the last week we managed to catch some of the Excelsior issues live and did some debugging on the SQL server with the instrumentation we deployed a few weeks ago. Unfortunately, we weren't able to track down the exact cause of the issue, even though we could see the symptoms clearly. Today, we deployed additional instrumentation to Excelsior to help diagnose the issue. We're hopeful this change will give us the remaining information we need to solve the problem. We also deployed some minor adjustments to various operations which can lag the SQL queue in the hope that this will help the issue. Lastly, several of you have followed up on your tickets; I've seen the forwards from the GM team and we'll continue working on them along with this issue.
-
I just wanted to follow up and say that we've discovered a few potential causes for the Excelsior issues. We'll be extending maintenance tomorrow and implementing some of the fixes to see if they help. Note that these are expected to help with the server slowdowns, but I do not believe they will help with superpack or auction claiming. If you've been having persistent issues with claiming and they persist beyond tomorrow's restart, please file a ticket and ask the GM team to direct it to me so that I can look into your account's database records in more detail. If you've already filed a ticket, please follow up on it with a note to bring it to my attention, and reference this post.
-
I just wanted to follow up and note that we're aware of the recent database/email/temporary server hang issues (largely affecting Excelsior but also affecting the other shards). The shards each have what is called an SQL Queue which contains pending database operations. Under normal operations, the queue is minimal - our servers are more than adequately provisioned to handle load. Some things can cause a large amount of database load (Hami raids, bulk email claims, and bulk superpack openings are among these). Thanks to some work Six did early on in Homecoming, we can normally handle these as well without significant issue. Recently we've been noticing SQL Queue spikes, which cause issues like the recent multi-minute hangs of Excelsior, and which are likely related to email claiming and superpack opening issues. We're adding additional instrumentation to find out what is causing these, and once we find the cause we'll fix it as quickly as possible. With luck, the full shard restart today will help ameliorate the issue for some of the people who have been suffering it. We know from past experience that some people may still be affected; please be assured we're working on the issue and will resolve it. Edit: This issue also can affect transfers between shards; we're working to resolve that as well.
- 85 replies
-
- 11
-
-
-
-
We had intended to open the donations yesterday, but unfortunately Cipher had some urgent personal business to attend to and wasn't able to complete the report in time. We expect donations for February to open on the normal Saturday the 26th. Also, thank you (and everyone) for your support!
-
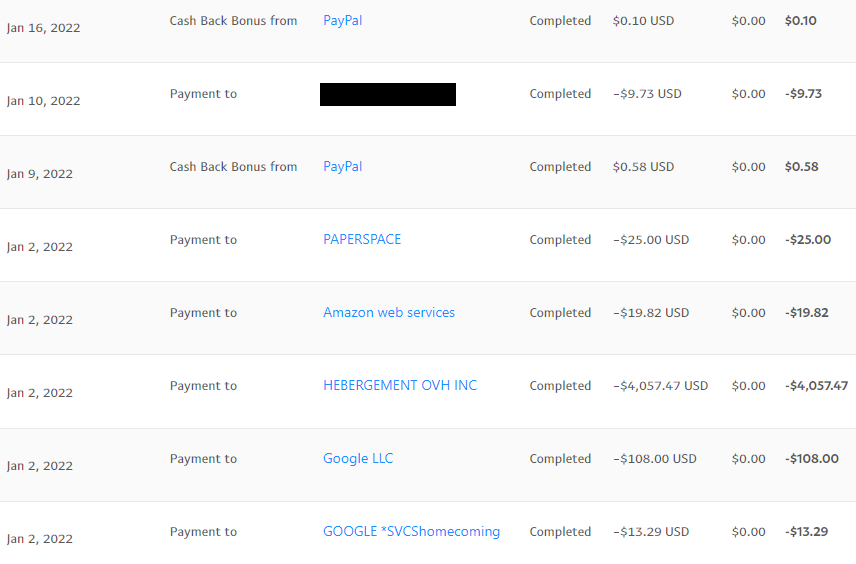
Update by @Cipher Hey all, apologies that our donations didn't open up at the normal time this month. This was an outlier for us and we'll be back to our normal schedule with the next donation window. Additionally, I hope to better our process so that we can still produce our monthly report and open donations on time in the event that I am unavailable to do so again in the future. I appreciate your patience and understanding. As of the time of this update, we now have $954.08 in excess funds. This money will be put towards our operating expenses for next month (March). If you have any questions about this, please let me know. Last Month: January 2021 Last month we accepted $4,302.91 in donations, $60.61 over our target for the month. As always, all remaining funds will be put towards our operating expenses for the upcoming month (March in this case due to the delay). Here is the breakdown of what January's funds went towards: $4,057.47 for our hardware infrastructure from OVH $121.29 for our Google G-Suite services $25.00 for our Air instance from Paperspace $19.82 for the AWS EC2 instance serving our email $9.73 for security / administration software (redacted below) This Month: February 2022 We do not have any changes or updates for this month. The donation target for February 2022 would have been $4,172.02. Here is a breakdown of how the funds are allocated: $4,057.47 for our hardware infrastructure from OVH $121.57 for our Google G-Suite services $25.00 for our Air instance from Paperspace $19.25 for the AWS EC2 instance serving our email $9.73 for security / administration software

-
Hello all, Unfortunately, CIpher is temporarily unavailable and unable to complete the finances report for Homecoming this month. However, as our OVH bill comes due on February 1st, we are opening donations for a total of $5,000.00 (last month's target was $4,242.30, as can be seen here). As usual, any additional amount will be applied to next month. Cipher will update this post and thread with the full report as soon as he is available. Our donation system will be open as of the time of this post with a donation target of $5,000.00 and will automatically close once that target is met. - The Homecoming Team
-
I just played around a little bit, and I think the set felt pretty good. The one thing I really wish is that the set had a Slow somewhere in it to combo with Meteor. Since Upthrust is an AoE and says it makes the enemies heavy, perhaps that could have a Slow added when empowered by shockwaves (ideally without consuming the shockwaves). If that's not feasible, then perhaps there could be an instant-hit Slow in the Meteor AoE, to keep enemies from running out of it while the main animation occurs. This could be short-duration (just the length of the animation itself).
-
If all goes well we'll be dropping our remaining four NA Advance-5 servers at the end of November. These cost us approximately $1300 for the November bill. The annoyance here was that we based our order date partly off OVH's delivery estimate (20-30 days) and while OVH has delivered servers late before, this is the first time we've received them early. If we had received the SCALE-3s in early to mid November as we expected, we would have had sufficient time to set them up and cancel the Advance-5s. The billing on the SCALE-3s is also thankfully not as bad as it seems - even though we were billed the full first month in advance, we will receive a prorated bill in the future to make the billing cycle match (note: this may cost us a small amount extra temporarily; I expect that in late November OVH will bill the SCALE-3s through either the beginning or end of December). So our SCALE-3s are actually paid up through late November, and long-term we are not paying extra for them. We've also gotten the network issue fixed and are proceeding with qualification and installation on them. I don't know if OVH will issue a credit, but we'll follow up on the ticket and see if we can get something from them. As far as non-binding estimates, please refer to my other post: The savings are so great from changing to the SCALE-3s that we'll still see our monthly costs go down; it will just take a little bit longer before they pay us back. We've already started getting some savings as we have already replaced two of our previous Advance-5s with the first SCALE-3 (going from six to the current four).
-
issue 27 Patch Notes for October 5th, 2021
Telephone replied to The Curator's topic in Patch Notes Discussion
Which launcher are you using? Please file a support ticket or log in to our Discord and look in the Help & Support channels. -
This is definitely an interesting idea. I'm unsure if this would be feasible, but @Number Six or @Faultline might have a lot more insight, so I am pinging them here to see if they have any thoughts on this matter. Thanks!
- 1 reply
-
- 1
-
-
A good question - unfortunately, I have to be the bearer of bad news with respect to most of what you mention: Faster Load Times Load times are almost entirely on the client and network side of things. The mapserver hosts actually keep the entirety of the City of Heroes dataset in memory (you may have heard occasional references to 'shared memory corruption', usually causing Ouro issues but also likely responsible for the recent unplanned restart of Reunion earlier this week, where Mercy Island was having issues loading). Because of this, the starting of a new mapserver process on the server side is very fast (it might take a short time if a new instance of a large city zone map is being spun up, but mission maps are usually much smaller, and the city zones don't tend to start new processes often). The bulk of the time would be spent loading the data on your PC and transferring the current state of the map over the network to you. There might be a tiny improvement from the faster CPU in initial map setup, but I don't think it will be measurable. Less Lag This is definitely something that could improve, but it depends heavily on the source of lag - the servers can't do anything about network lag. That said, sometimes very heavily loaded maps do peg out the CPU (a given map is mostly single-threaded on the servers), so during Hami raids or other extremely busy events, there might well be some improvement here. We've also got some other development work in the pipeline which I am not at liberty to divulge, but which could improve lag as well! (And not just server lag - we've got some ideas on network lag which may bear fruit). More Responsive /AH Wentworth's has elected to spend their money on new monocles this year instead of improving the market experience. More seriously, the /AH issues are fundamental architectural issues in how the entire system works. There's definitely a desire to improve the experience, but throwing hardware at it won't improve it much. At some point in the future the system will probably get an overhaul to move to a more modern database architecture and do a general cleanup. We do occasionally discover low-hanging fruit in the AH system and when we do, we try to fix those issues to improve the experience, but the system is badly in need of an overhaul. Other Notes OVH decided to redesign how networking works on their high-performance servers. It actually took us a good part of today to get the public networking set up on the new host (our private vRack worked much more quickly, thankfully) and pass it through to the mapserver host VM within, but everything seems to be working now. It's very likely that at next week's restart we'll put one of the NA shards entirely on the new host to see how it works out.
-
We (finally) received our first SCALE-3 last week. We've been setting it up, and will likely be stress-testing it soon. More details to follow!
-
Beacons are the means by which AI can traverse maps efficiently. On live, there was actually a process called BeaconServer which worked to beaconize bases during play - which is one of the reasons live had such Draconian limits on base items, because generating beacons is a very expensive process (and the cost is not linear, especially when cramming many objects into a small area). Homecoming does not run BeaconServer and allows much more extensive base-building; the cost for this is that there can be no real combat in bases. In the earliest days of Homecoming, we had no issues spinning up plenty of hosts to handle mapserver load (we were using high-performance VMs until we moved to OVH). The problem we encountered is that player load on a shard is not linear - no matter how much power you throw at it, due the fundamental design of CoH's database system, a shard quickly reaches a saturation point between 2,000 and 3,000 players. Homecoming's shards can handle roughly 2,500 players per shard with some lag (Reunion only 1,500 with its current setup, because it has only one mapserver host); even allocating the largest VMs available (32 cores at the time), we were unable to push a shard to 3,000 players before the dbserver collapsed (even 8 cores on the dbserver host were able to handle 2,000 players; I can't recall if we bumped it more to reach 2,500 at the time). Homecoming's peak was 9.998 active players over Memorial Day weekend 2019 (believe me, we wish we had hit that magic 10,000, just because).
-
Thanks very much for the suggestion! We're always looking at ways to reduce our expenses. I did spend some time reviewing Datapacket, and unfortunately, for the servers we need (even if we were to reduce our redundancy level), they would be significantly more expensive than OVH is for us. Please check out Cipher's excellent post from last year where he goes into a deep dive on our finances: We do review our hardware periodically and are in the middle of a process to consolidate some of our hosts, reducing costs. Due to limited hardware availability (I suspect the chip shortage may have something to do with this), this is taking longer than we had expected (but the charges for our new hardware will not begin until it actually arrives).
-
Not at all. The new SCALE-3 has not yet arrived, and the failed host was cancelled and removed from our cluster as of June 1st, several weeks ago. We've actually evaluated AWS before. Unfortunately, their pricing and price/performance is not competitive with what we can get from OVH. Another major issue that we would run into is that the architecture of CoH is not amenable to ramping up and down mapserver hosts (we do have some custom features for scaling and draining on Homecoming thanks to Number Six's awesome work, but we'd have to do a lot of operational work to be able to scale servers the way GameLift expects).